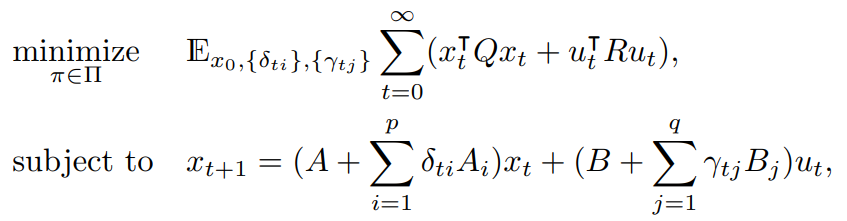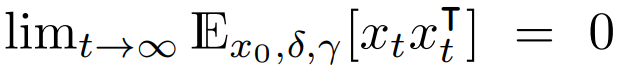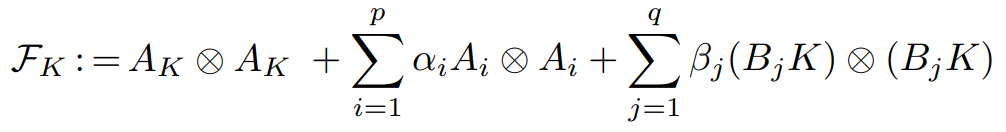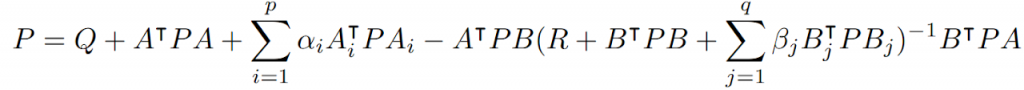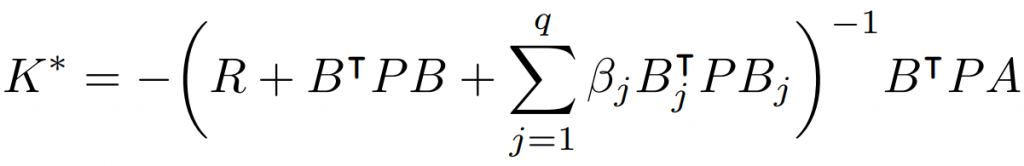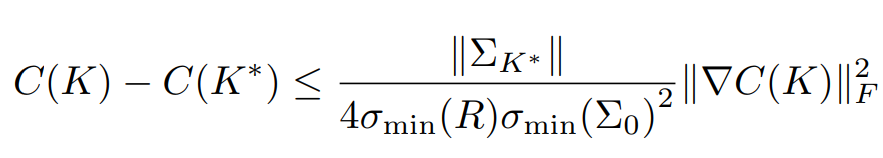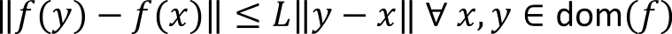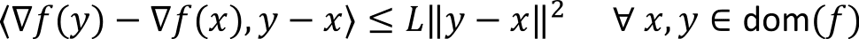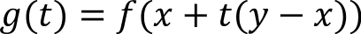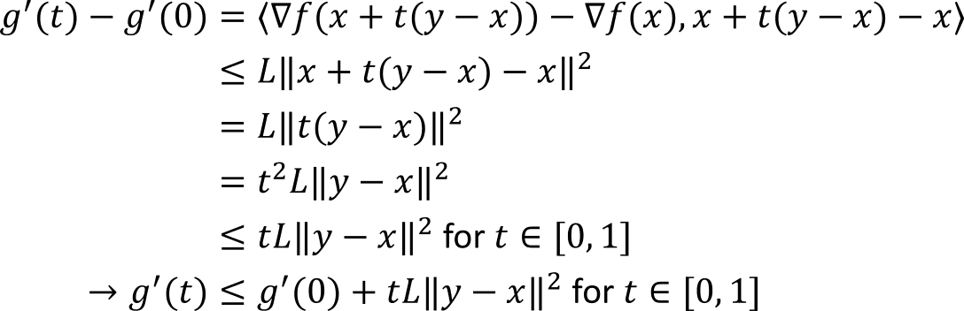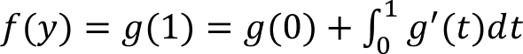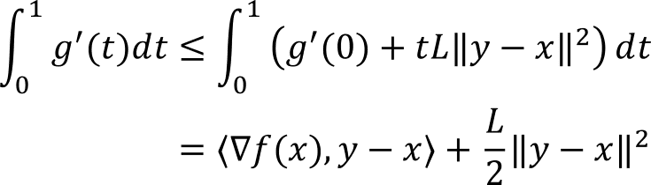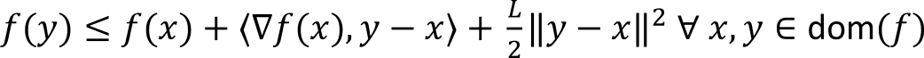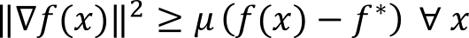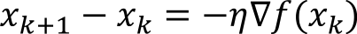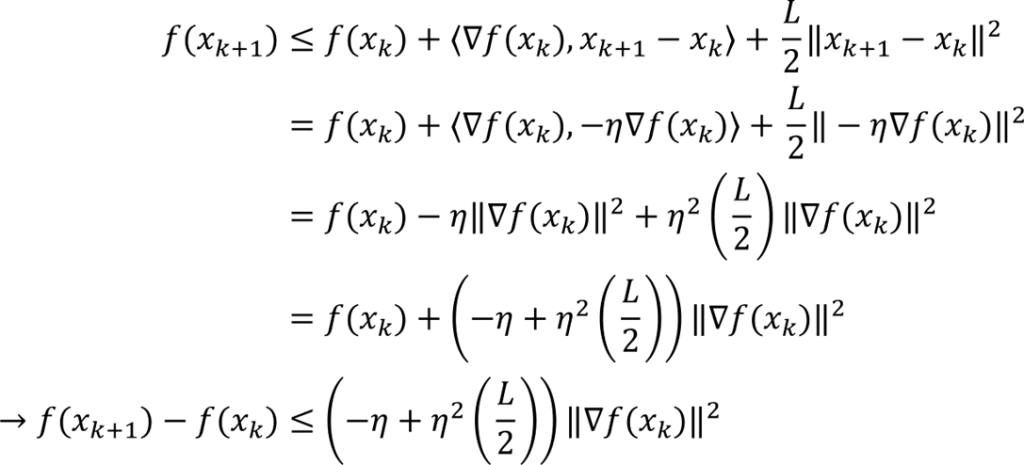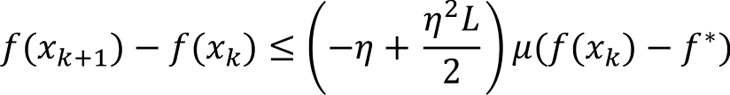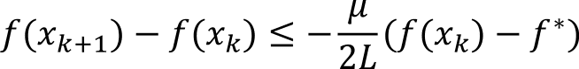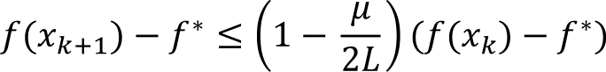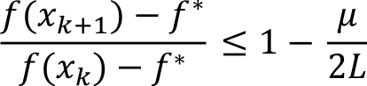Example of Google Brain’s permutation-invariant reinforcement learning agent in the CarRacing environment
In a paper accepted to the upcoming NeurIPS 2021 conference, researchers at Google Brain created a reinforcement learning (RL) agent that uses a collection of sensory neural networks trained on segments of the observation space and uses an attention mechanism to communicate information between the sensory networks. The interactive demo shows that an agent trained to balance a cartpole (the CartPoleSwingUpHarder environment) can continue to succeed at its task even when the order of the observations is permuted during operation in real time – very impressive! The other videos show similar performance on the PyBullet Ant robot environment and simple videogame environments.
Allow me to address an important concept in RL that will make the performance of these agents even more remarkable and perhaps surprising. Perhaps the most persistent and onerous concern in data-driven control is robustness to uncertainty. Uncertainties can arise due to inherent time-varying randomness in the environment, as well as (nearly-)static changes in the environment which manifest as distribution shift in data observed by a controller. A standard trick in RL to promote robustness is domain randomization. In this procedure, certain aspects of the environment are changed during training of a control policy. In so doing, the learner is exposed to a wider variety of situations, which are presumed to somehow make the learner “aware” of the potential uncertainties that exist and hence learns a policy that accounts for these uncertainties.
The simplest optimal control task is linear quadratic regulation (LQR), which has been argued as the natural starting point for analysis of learning-based control:
“If a machine learning algorithm does crazy things when restricted to linear models, it’s going to do crazy things on complex nonlinear models too.”
Analogously, I argue that multiplicative noise (aka stochastic system parameters) is the simplest type of domain randomization for learning-based control. Our group has extensively studied the properties of linear systems with multiplicative noise in learning-based control, and established both theoretically and empirically that designing (training) controllers in the presence of multiplicative noise does indeed produce robustness of stability to parameter uncertainty.
What is amazing about Google Brain’s permutation-invariant agents is that they achieve permutation-invariance without the need for domain randomization; during training, the order of the observations was kept constant, and only at test time was the observation ordering permuted. In fact, the permutation-invariance is explicitly considered through the design of the attention mechanism, which merges the outputs of the sensory neurons in a permutation-invariant way. This suggests that the need for domain randomization during training can be obviated if the form of the domain uncertainty is known ahead of time and can be designed into the control policy architecture.
I leave the reader with a natural follow-on question:
Is there an analogous way to design a control policy architecture that is robust to system parameter uncertainties without the need for domain randomization during training?
Their research suggests that adversarial training of neural network-based image classifiers, when applied in robot learning settings, can have the opposite of the intended effect, i.e. that adversarially-trained classifiers lead to less safe system operation than their nominal counterparts.
This work highlights the importance in aligning the specification of the adversarial training and the control objective. In particular, they demonstrate that the intuitive low-level training goal of maintaining high image classification accuracy under norm-bounded adversarial perturbations is not sufficient to provide the high-level goal of maintaining high safety of system trajectories under the same adversarial perturbations. This suggests that, to achieve true safety, some type of coupling between high-level control and low-level image classification must be enforced during training.
This work also highlights the large gap between theory and practice in data-driven control. In the literature on statistical learning for linear systems, rigorous guarantees of robustness are typically provided in a classical systems-theoretic sense e.g. ensuring stability of a system subject to model uncertainties and process + measurement disturbances.
For instance, in the CONLab work “Policy Iteration for Linear Quadratic Games with Stochastic Parameters” (IEEE Xplore) (ResearchGate) we consider the setting of a linear system with full-state linear feedback control. We combine stochastic parameters as a device during control design to induce robustness to structured parametric uncertainty, with additive adversarial disturbances to handle unstructured model uncertainty. We also draw an analogy with the machine learning literature, where unstructured uncertainty is addressed by adversarial training examples, while structured uncertainty is addressed by domain randomization.
On the other hand, to control more complicated nonlinear systems, practitioners often use highly expressive neural networks for encoding and approximating value functions and control policies, as well as for processing raw measurements e.g. LiDAR and video image data, whose post-training behavior is not fully understood. Ensuring safety of neural network-based controllers in robot applications may be possible if the control safety can be meaningfully related to the neural network sensitivity using e.g. the Lipschitz constant (e.g. “Efficient and Accurate Estimation of Lipschitz Constants for Deep Neural Networks” arXiv) or constraining predictions to a safety set in the output space (e.g. “Safety Verification and Robustness Analysis of Neural Networks via Quadratic Constraints and Semidefinite Programming” arXiv).
Kudos to the authors Lechner, Hasani, Grosu, Rus, and Henzinger for alerting practitioners to the dangers of naively applying adversarial training in robot learning. We will do our part to bridge the theory practice gap and provide techniques for achieving true safety in data-driven robot operations.
We propose a robust adaptive control algorithm that explicitly accounts for inherent non-asymptotic uncertainties arising from models estimated with finite, noisy data. The algorithm has three components: (1) a least-squares nominal model estimator; (2) a bootstrap resampling method that quantifies non-asymptotic variance of the nominal model estimate; and (3) a non-conventional robust control design method using an optimal linear quadratic regulator (LQR) with multiplicative noise. A key advantage of the proposed approach is that the system identification and robust control design procedures both use stochastic uncertainty representations, so that the actual inherent statistical estimation uncertainty directly aligns with the uncertainty the robust controller is being designed against. Numerical experiments show significant improvements over the certainty equivalent controller on both expected regret and measures of regret risk.
We give novel characterizations of the uncertainty sets that arise in the robust linear quadratic regulator problem, develop Riccati equation-based solutions to optimal robust LQR problems over these sets, and give theoretical and empirical evidence that the resultant robust control law is a natural and computationally attractive alternative to the certainty-equivalent control law when the pair (A, B) is identified under l2-regularized linear least-squares.
Many thanks to Wouter Jongeneel and Dr. Peyman Esfahani at TU Delft for their collaboration on this work. Wouter has just finished his master’s thesis and is starting a PhD at EPFL under Daniel Kuhn January 2020 – congratulations!
We show that the linear quadratic regulator with multiplicative noise (LQRm) objective is gradient dominated, and thus applying policy gradient results in global convergence to the globally optimum control policy with polynomial dependence on problem parameters. The learned policy accounts for inherent parametric uncertainty in system dynamics and thus improves stability robustness. Results are provided both in the model-known and model-unknown settings where samples of system trajectories are used to estimate policy gradients.
Policy gradient is a general algorithm from reinforcement learning; see Ben Recht’s gentle introduction. At a high level, it is simply the application of (stochastic) gradient descent to the parameters of a parametric control policy. Although traditional reinforcement learning treats the tabular setting with discrete state and action spaces, most real-world control problems deal with systems that have continuous state and action spaces. Luckily, policy gradient works much the same way in this setting.
In this post we walk through some of the key points from our paper; see the full text for more details and variable definitions.
Setting: LQR with multiplicative noise
We consider the following infinite-horizon stochastic optimal control problem with an objective quadratic in the state and input with stochastic dynamics with multiplicative noises (LQRm problem). Expectation is with respect to the initial state and the multiplicative noise.
Any solution to this problem must be stabilizing, however in the context of stochastic systems we must deal with a stronger form of stability known as mean-square stability which requires not only that the expected state return to the origin over time, but also that the (auto)covariance of the state decrease to zero over time:
Mean-square stability:
Mean-square stability can be further characterized in terms of the vectorized state covariance dynamics operator
The LQRm problem is special since it, like the deterministic LQR problem, admits a simple solution which is computable from a Riccati equation, specifically this one:
However, unlike the LQR problem with additive noise, the multiplicative noises change the optimal gain matrix relative to the deterministic case. In particular, the multiplicative noise can be used as a proxy for uncertainty in the model parameters of a deterministic linear model.
Motivation: robust stability
A key issue in control design is robustness i.e. ensuring stability in the presence of model parameter uncertainty. The following example motivates how stochastic multiplicative noise ensures deterministic robustness.
Although this is a simple example, it demonstrates that the robustness margin increases monotonically with the multiplicative noise variance. We also see that when α = 0 the bound collapses so that no robustness is guaranteed, i.e., when |a| → 1. This result can be extended to multiple states, inputs, and noise directions, but the resulting conditions become considerably more complex.
Case of known dynamics
We already saw that we can solve the optimal control problem exactly (up to a Riccati equation), so what else is there to study? We ultimately care about the case when dynamics are unknown (e.g. as in adaptive control or system identification) which can be handled by policy gradient.
To begin we see how policy gradient works when the dynamics are fully known, in which case the policy gradient can be evaluated analytically in terms of the dynamics:
With this expression, we can prove the key result that the LQRm objective is gradient dominated in the control gain matrix K:
This (along with Lipschitz continuity) immediately implies that (policy) gradient descent with an appropriate constant step size will converge to the global minimum, i.e. the same solution found by solving a Riccati equation, at a linear (geometric) rate from any initial point. For those familiar with convex optimization, gradient domination bears some similarities to the more restrictive strong convexity condition, which essentially puts a lower bound on the curvature of the function, thus ensuring gradient descent makes sufficient progress at each step anywhere on the function. See Theorem 1 of this paper for an extremely short proof of convergence under the gradient domination (Polyak-Lojasiewicz) condition.
The bulk of the technical work that follows goes towards bounding the Lipschitz constant, and thus the step size and convergence rate. We also analyze the natural policy gradient and “Gauss-Newton” steps in parallel to Fazel et al. – these steps give faster convergence than vanilla policy gradient but require more information. Note that “Gauss-Newton” step with a stepsize of 1/2 is exactly the policy iteration algorithm (another model-free RL technique) first proven to converge for standard LQR in the case of known dynamics in continuous-time by Kleinman in 1968 and in discrete-time by Hewer in 1971 and in the case of unknown dynamics by Bradtke, Ydstie, and Barto at the 1994 ACC. Note that many authors from the 1960s and 1970s did not frame their results under the modern dynamic programming/reinforcement learning labels of “policy iteration” or “Q-learning” but rather as iterative solutions of Riccati equations.
Case of unknown dynamics
When the dynamics are unknown, the (policy) gradient must be obtained empirically via estimation from sample trajectories. We use the following algorithm to do this:
In this case, we use tools from high-dimensional statistics known as concentration bounds to ensure that with high probability the error between the estimated and true gradients is smaller than a threshold. The threshold is chosen small enough that gradient descent with the same step size as in the case of exact gradients provably converges.
Numerical experiments
We validated policy gradient in the case of known dynamics – this is much faster to simulate than the case of unknown dynamics due to the large number of samples required to estimate the policy gradient accurately.
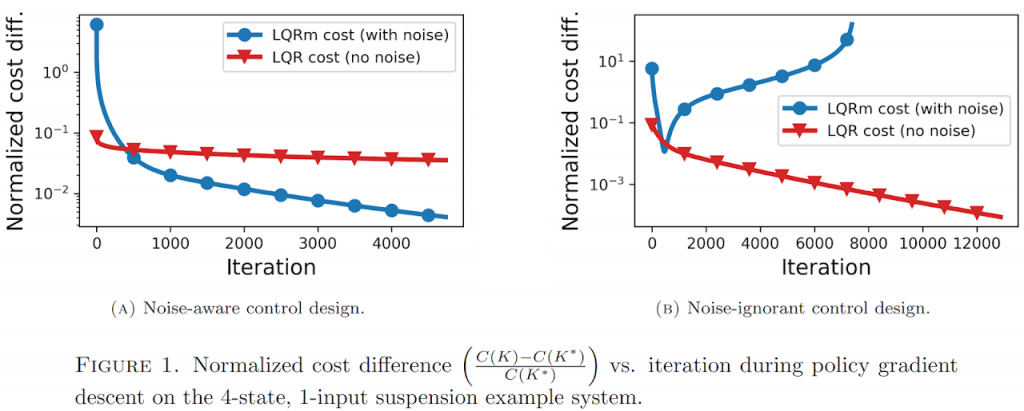
The first example shows policy gradient working on a suspension system with 2 masses (4 states) and a single input. To demonstrate the peril of failing to account for multiplicative noise when it truly exists, we ran policy gradient both (a) accounting for and (b) ignoring the multiplicative noise. The blue curves show the control evaluated on the LQR cost with multiplicative noise while the red curves show the control evaluated on the LQR cost without multiplicative noise. When the noise is ignored, the control destabilized the truly noisy system in mean-square. When noise is assumed, the control achieves lower performance on the truly noiseless system, but does not and cannot destabilize it.
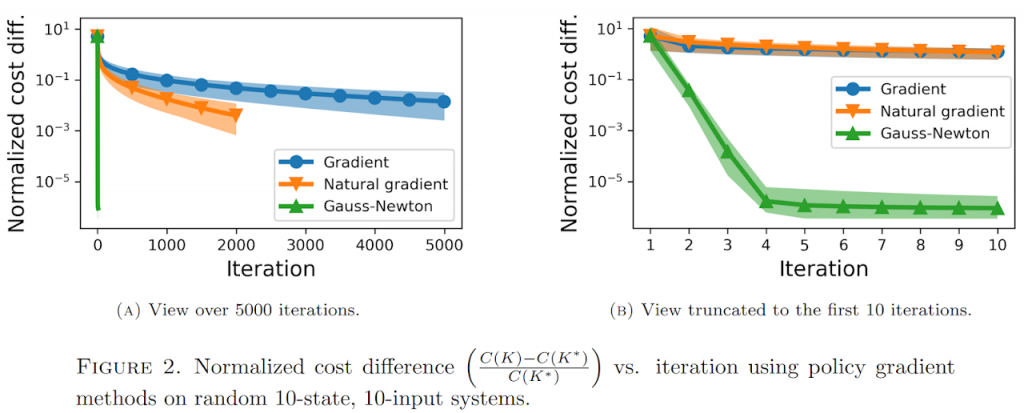
The second example shows policy gradient and its faster cousins applied on a random 10-state, 10-input system. With more iterations, the global optimum is more closely approximated.
Opinions & take-aways
Although the techniques used in this work and Fazel et al. represent a novel synthesis of tools from various mathematical fields, simpler/shorter proofs would help reduce barriers-to-entry for controls researchers unfamiliar with the finer points of reinforcement learning and statistics.
Convergence results were shown, but sample efficiency is still a major concern. Model-based techniques have been shown to be significantly more efficient for learning to control linear systems. This is somewhat expected since a linear dynamics model is the simplest possible; model-free techniques may be competitive when the dynamics are highly nonlinear and difficult to model based solely on data.
Related work
We envision multiplicative noise as a modeling framework for ensuring robustness; see older work from Bernstein which informs this notion. Perhaps the best known framework for robustness in multivariate state space control is H-infinity control. Applying policy gradient to the dynamic game formulation of this framework has received attention lately as well; see positive results in the two-player setting and negative results in the many-player setting.
We came across these interesting works that are somewhat tangential to our interests, but fascinating all the same.
Physics in N dimensions
Marc ten Bosch developed a formulation for rigid body dynamics that is independent of the dimension of the space, which is described using geometric algebra. An interesting issue that was also solved was that of collision resolution, which is handled elegantly for convex polytopes which are sufficient to represent typical objects to a high level of accuracy. The paper was accepted to SIGGRAPH 2020 and has been implemented as the commercially available 4D toys as well as an upcoming computer game. Two Minute Papers also covered this game/research.
Reaction-diffusion dynamics
Reaction-diffusion dynamics generalize the diffusion-only dynamics readers may be familiar with from the field of networked systems, which can actually be thought of as a discretization of the diffusion/heat partial differential equation. When the new reaction term is added, rather interesting behavior emerges due to the nonlinearities in the dynamics.
This page shows Robert Munafo’s exploration of different regimes of the parameter space of the reaction-diffusion dynamics.
One particularly interesting setting is called the “U-skate world,” which exhibits emergent patterns somewhat similar to Conway’s Game of Life e.g. the appearance of “still-lifes,” small portions of the state-space that retain their structure over time and “gliders,” small portions of the state-space that both retain their structure over time and move across the state-space by delicate balancing of the forces over their bodies.
SmoothLife
Conway’s Game of Life was a seminal development in computer science that spurred thought about information theory. It was a simple set of rules meant to mimic conditions of population pressures and incentives in living creatures, known as a cellular automata. The game is played on a grid and each cell has a binary state which is updated at discrete time steps. Stephan Rafler generalized the mathematical formulation of this game to continuous state and time, leading to qualitatively similar behavior as Conway’s Game, but with much more organic and arguably richer phenomena, including self-propelled gliders and chain-like structures. Check out the paper, the code, and some YouTube videos. Lex Fridman also interviewed Stephen Wolfram, another giant of computing, wherein they discussed cellular automata.
Inaugural Bode Lecture by Dr. Gunter Stein, CDC, 1989
Keywords: Stability, robustness, fundamental limitations, Bode integral, sensitivity, waterbed effect
Summary
In this classic entertaining lecture delivered by Dr. Gunter Stein, fundamental limitations arising in control pertaining to stability, performance, and robustness are addressed. In particular, the Bode integral is advocated as a fundamental “conservation law” of control, despite its relative obscurity at the time, which arguably persists to this day. Other highlights include demonstrations of the effect of unstable poles both on the ubiquitous simple inverted pendulum, as well as the then-state-of-the-art X-29 aircraft with forward-swept wings; these two systems are more similar than a passing glance would suggest! Dr. Stein’s prescient observations on the twin trends of ever more dangerous systems being controlled and increasing detachment of control theoreticians from these systems, whether due to over-emphasis on formal mathematics or due to automatic “optimal” control synthesis, are perhaps more sobering than ever today in light of recent developments in autonomous driving systems, power networks, and data-driven learning control.
Work by Hamed Karimi, Julie Nutini, and Mark Schmidt, ECML PKDD 2016
Keywords: Nonconvex, optimization, Polyak-Lojasiewicz inequality, gradient domination, convergence, global
Summary
The authors re-explore the Polyak-Lojasiewicz inequality first analyzed by Polyak in 1963 by deriving convergence results under various descent methods for various modern machine learning tasks and establishing equivalences and sufficiency-necessity relationships with several other nonconvex function classes. A highlight of the paper is a beautifully simple proof of linear convergence using gradient descent on PL functions, which we walk through in our discussion.
Convergence of gradient descent under the Polyak-Lojasiewicz inequality
This proof is extremely short and simple, requiring only a few assumptions and a basic mathematical background. It is strange that it is as universally known as the theory related to convex optimization.
Relating to the theory of Lyapunov stability for nonlinear systems, the PL inequality essentially means that the function value itself is a valid Lyapunov function for exponential stability of the global minimum under the nonlinear gradient descent dynamics.
Applying the Cauchy-Schwartz inequality to the Lipschitz gradient condition gives
Define the function g(t) as
If the domain of f is convex, then g(t) is well-defined for all t in [0, 1].
Using the definition of g(t), the chain rule of multivariate calculus, and the previous inequality we have
Using the definition of g(t) we can rewrite f(y) in terms of an integral by using the fundamental theorem of calculus
Integrating the second term from 0 to t and using the previous inequality and the derivative of g(t) we obtain
Substituting back into the expression for f(y) we obtain the quadratic upper bound
The Polyak-Lojasiewicz inequality
A function is said to satisfy the Polyak-Lojasiewicz inequality if the following condition holds:
where f* is the minimum function value.
This means that the norm of the gradient grows at least as fast as a quadratic as the function value moves away from the optimal function value.
Additionally, this implies that every stationary point of f(x) is a global minimum.
Gradient descent
The gradient descent update simply takes a step in the direction of the negative gradient:
We are now ready to prove convergence of gradient descent under the PL inequality i.e. Theorem 1 of Karimi et al.
Rearranging the gradient descent update gives the difference
Using the gradient descent update rule in the quadratic upper bound condition (from Lipschitz continuity of the gradient) we obtain
If the stepsize is chosen so that the coefficient on the righthand side is negative, then using the Polyak-Lojasiewicz inequality gives
The range of permissible stepsizes is [0, 2/L] with the best rate achieved with a stepsize of 1/L. Under this choice, we obtain
Adding f(x_k) – f* to both sides gives
Dividing by f(x_k) – f* gives the linear (geometric) convergence rate
This shows that the difference between the current function value and the minimum decreases at least as fast as a geometric series with a rate determined by the ratio of the PL and Lipschitz constants.
Why would control systems researchers care about this?
This work extends results on convergence of policy gradient methods for discrete-time systems of Fazel et al. to the case of continuous-time linear dynamics while also significantly improving the number of cost function evaluations and simulation time. These improvements were made possible by novel proof techniques which included 1) relating the gradient-flow dynamics associated with the nonconvex formulation to that of a convex reparameterization, and 2) relaxing strict bounds on the gradient estimation error to probabilistic guarantees on high correlation between the gradient and its estimate. This echoes the notion that indeed “policy gradient is nothing more than random search“, albeit a random search with compelling convergence properties.