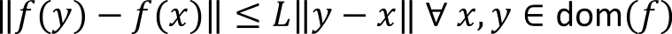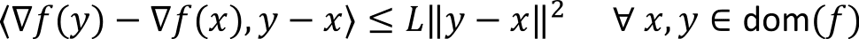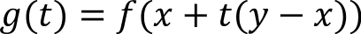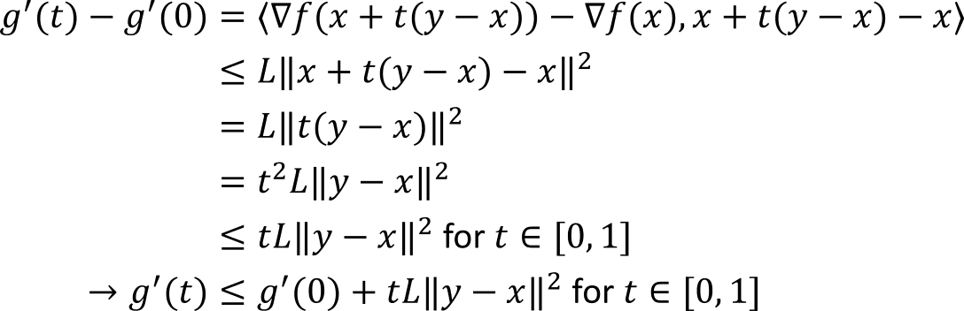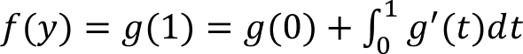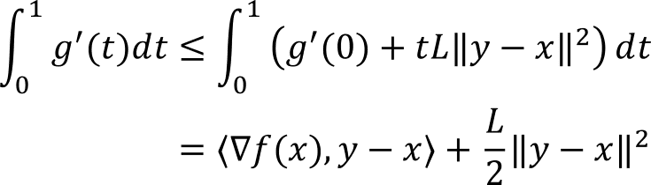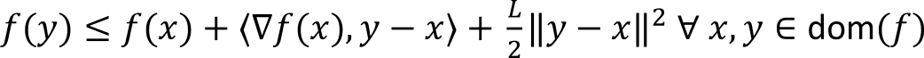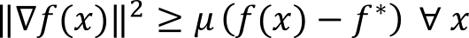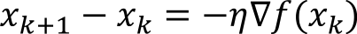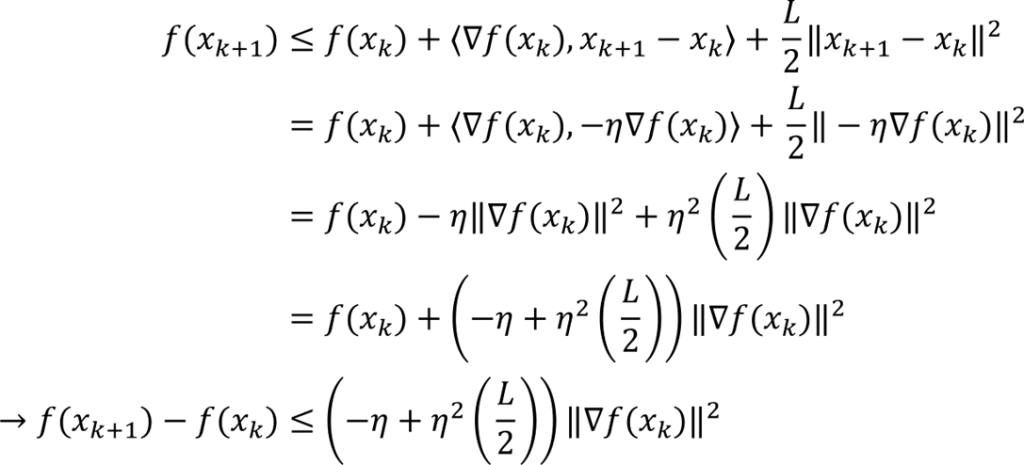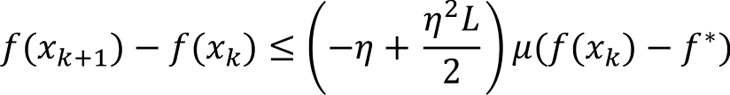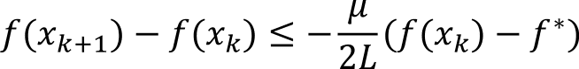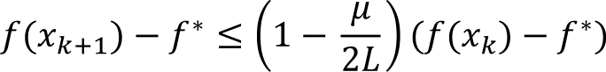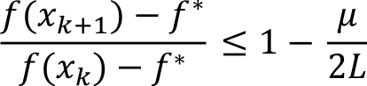Work by Zhangjing Wang, Yu Wu, and Qingqing Niu, IEEE Access Volume: 8, 2020
Keywords: Multi Sensor Fusion, Autonomous Driving, Tracking, Data Association
Summary
The authors present a survey for multi-source and heterogeneous information fusion for autonomous driving vehicles. They discuss three main topics:
Sensors and communications: identifying the most popular sensors and communication schemes for autonomous driving and their advantages and disadvantages
Fusion: dividing fusion approaches into four main strategies: discernible units, feature complementarity, target attributes of different sensors, and decision making of different sensors.
Data association: describing methods for data association for single or multiple sensors detecting spare or multiple targets.
Work by Dimitris Bertsimas & Ioana Popescu, SIAM Journal on Optimization, Volume: 15, Number: 3, Pages: 780-804, 2005
Keywords: Bounds in Probability Theory , Higher Order Moment Based SDP
Summary
The authors investigate the problem of obtaining best possible bounds on the probability that a certain random variable belongs in a given set, given information on some of its moments (up to kth-order) famously called as the (n, k, Ω)-bound problem. They formulate it as an optimization problem and use modern optimization theory, in particular convex and semidefinite programming. In particular, they provide concrete answers to the following three key questions namely:
Are such bounds “best possible”; that is, do there exist distributions that match them?
Can such bounds be generalized in multivariate settings, and in what circumstances can they be explicitly and/or algorithmically computed?
Is there a general theory based on optimization methods to address in a unified manner moment-inequality problems in probability theory?
Key Observations
In the univariate case, optimal bounds on P(X ∈ S), when the first k moments of X are given, is given by the solution of a SDP in k + 1 dimensions, where S denotes the set of interest.
In the multivariate case, if the sets S and Ω are given by polynomial inequalities, an improving sequence of bounds are obtained by solving SDPs of polynomial size in n, for fixed k.
It is NP-hard to find tight bounds for k ≥ 4 and Ω = Rn and for k ≥ 2 and Ω = Rn+ respectively with rational problem data.
For k = 1 and Ω = Rn+, it is possible to find tight upper bounds by solving n convex optimization problems when the set S is convex and a polynomial time algorithm is given when S and Ω are unions of convex sets, over which linear functions can be optimized efficiently.
For k = 2 and Ω = Rn, authors present an algorithm for finding tight bounds when S is a union of convex sets, over which convex quadratic functions can be optimized efficiently.
Possible Applications of Ideas Presented in this Paper
Propagating uncertainties in risk-bounded motion planning with the risk of a trajectory being quantified using the probability bounds presented in this paper
Anomaly detection in cyber physical systems where higher order moments of a residual data from a state estimator can be used to design anomaly detector thresholds that can satisfy an user prescribed false alarm rate.
Work by Curtis Madsen, Prashant Vaidyanathan, Sadra Sadraddini, Cristian-Ioan Vasile, Nicholas A. DeLateur, Ron Weiss, Douglas Densmore, and Calin Belta, IEEE CDC 2018
Keywords: Signal Temporal Logic, Metric Spaces
Summary
The authors discuss how STL formulae can admit a metric space under mild assumptions. They present two metrics: the Pompeiu-Hausdorff (PH) and the Symmetric Difference (SD) metrics. The PH distance measures how much the language of one formula needs to be enlarged to include the other. The SD distance measures the overlap between the two formulae. The PH distance can be formulated as a Mixed-Integer Linear Programming (MILP) optimization problem which can be computed fairly quickly (although complexity grows exponentially with the number of predicates are formulae horizon). The SD distance is computed using a recursive algorithm based on the area of satisfaction. Its complexity depends on the complexity of the norm operation.
Work by Tao Yang, et al., Annual Reviews in Control 2020
Discussion by Yi Guo, February 18, 2020
Keywords: Control review, distributed optimization, algorithm design
Summary
In distributed optimization of multi-agent systems, agents cooperate to minimize a global function which is a sum of local objective functions. Motivated by applications including power systems, sensor networks, smart buildings, and smart manufacturing, various distributed optimization algorithms have been developed. In these algorithms, each agent performs local computation based on its own information and information received from its neighboring agents through the underlying communication network, so that the optimization problem can be solved in a distributed manner.
This survey paper aims to offer a detailed overview of existing distributed optimization algorithms and their applications in power systems. More specifically, the authors first review discrete-time and continuous-time distributed optimization algorithms for undirected graphs. The authors then discuss how to extend these algorithms in various directions to handle more realistic scenarios. Finally, the authors focus on the application of distributed optimization in the optimal coordination of distributed energy resources.
Work by Samira S. Farahani, Rupak Majumdar, Vinayak S. Prabhu, and Sadegh Soudjani, IEEE Transactions on Automatic Control August 2019
Keywords: Signal temporal logic, model predictive control, stochastic disturbances
Summary
The authors discuss a shrinking horizon model predictive control (SH-MPC) problem to generate control inputs for a discrete-time linear system under additive stochastic disturbance (either Gaussian or bounded support). The system specifications are through a signal temporal logic (STL) formula and encoded as a chance constraint into the SH-MPC problem. The SH-MPC problem is optimized for minimum input and maximum robustness.
The authors approximate the system robustness in the objective function using min-max and max-min canonical forms of min-max-plus-scaling (MMPS) functions. They under approximate the chance constraint by showing that any chance constraint on a formula can be transformed into chance constraints on atomic propositions, then they transform the latter into linear constraints.
Read the paper on arXiv here or on IEEE Xplore here.
Work by Hamed Karimi, Julie Nutini, and Mark Schmidt, ECML PKDD 2016
Keywords: Nonconvex, optimization, Polyak-Lojasiewicz inequality, gradient domination, convergence, global
Summary
The authors re-explore the Polyak-Lojasiewicz inequality first analyzed by Polyak in 1963 by deriving convergence results under various descent methods for various modern machine learning tasks and establishing equivalences and sufficiency-necessity relationships with several other nonconvex function classes. A highlight of the paper is a beautifully simple proof of linear convergence using gradient descent on PL functions, which we walk through in our discussion.
Convergence of gradient descent under the Polyak-Lojasiewicz inequality
This proof is extremely short and simple, requiring only a few assumptions and a basic mathematical background. It is strange that it is as universally known as the theory related to convex optimization.
Relating to the theory of Lyapunov stability for nonlinear systems, the PL inequality essentially means that the function value itself is a valid Lyapunov function for exponential stability of the global minimum under the nonlinear gradient descent dynamics.
Applying the Cauchy-Schwartz inequality to the Lipschitz gradient condition gives
Define the function g(t) as
If the domain of f is convex, then g(t) is well-defined for all t in [0, 1].
Using the definition of g(t), the chain rule of multivariate calculus, and the previous inequality we have
Using the definition of g(t) we can rewrite f(y) in terms of an integral by using the fundamental theorem of calculus
Integrating the second term from 0 to t and using the previous inequality and the derivative of g(t) we obtain
Substituting back into the expression for f(y) we obtain the quadratic upper bound
The Polyak-Lojasiewicz inequality
A function is said to satisfy the Polyak-Lojasiewicz inequality if the following condition holds:
where f* is the minimum function value.
This means that the norm of the gradient grows at least as fast as a quadratic as the function value moves away from the optimal function value.
Additionally, this implies that every stationary point of f(x) is a global minimum.
Gradient descent
The gradient descent update simply takes a step in the direction of the negative gradient:
We are now ready to prove convergence of gradient descent under the PL inequality i.e. Theorem 1 of Karimi et al.
Rearranging the gradient descent update gives the difference
Using the gradient descent update rule in the quadratic upper bound condition (from Lipschitz continuity of the gradient) we obtain
If the stepsize is chosen so that the coefficient on the righthand side is negative, then using the Polyak-Lojasiewicz inequality gives
The range of permissible stepsizes is [0, 2/L] with the best rate achieved with a stepsize of 1/L. Under this choice, we obtain
Adding f(x_k) – f* to both sides gives
Dividing by f(x_k) – f* gives the linear (geometric) convergence rate
This shows that the difference between the current function value and the minimum decreases at least as fast as a geometric series with a rate determined by the ratio of the PL and Lipschitz constants.
Why would control systems researchers care about this?
This work extends results on convergence of policy gradient methods for discrete-time systems of Fazel et al. to the case of continuous-time linear dynamics while also significantly improving the number of cost function evaluations and simulation time. These improvements were made possible by novel proof techniques which included 1) relating the gradient-flow dynamics associated with the nonconvex formulation to that of a convex reparameterization, and 2) relaxing strict bounds on the gradient estimation error to probabilistic guarantees on high correlation between the gradient and its estimate. This echoes the notion that indeed “policy gradient is nothing more than random search“, albeit a random search with compelling convergence properties.
Keywords: Linear quadratic regulator, information, theory, regularization, matrix inequality, iterative
Summary
Researchers from UT Austin formulate a problem of jointly optimizing quadratic cost of a linear system and an information-theoretic communication cost which accommodates partial channel capacity. It is demonstrated empirically that this optimization can be solved with an iterative semidefinite program (SDP), and that the communication cost acts as a regularizer on the control gains, which in some cases promotes sparsity. This is similar to our own work on learning sparse control; we would love to see how data driven approaches could augment info-theoretic notions in the case of unknown dynamics.
Paper link is forthcoming once the CDC proceedings have been published. Author website is here.
Work by Javier Tapia, Espen Knoop , Mojmir Mutny, Miguel A. Otaduy, and Moritz Bacher, 2020
Keywords: Convex, optimization, feasible, design
Summary
Researchers at Disney have created a method for doing optimized sensor selection for soft robotics. A large number of presumptive fabricable sensors are virtually generated and are then culled down to a small set which give good pose estimation in simulation. They then verify the method experimentally by fabricating physical soft robots with highly elastic strain sensors embedded in a flexible polymer. Although our own research is geared toward theoretical analysis of sensor and actuator selection in the case of well-defined networked linear systems, we found this study a fascinating tangent.