Community Detection & Inference on Graphs
Community detection and clustering are central problems in machine learning and data mining. Large subsets of data can be represented as networks of interacting items, where one of the key features of interest is to understand which items belong together or have similar properties. This can be a goal unto itself, or a first step toward other learning tasks. Community detection has a wide and increasing set of applications, from biology to criminology, social networks, politics, link prediction, advertising, and other business activities.
In almost every practical application involving graphs, there also exist non-graph data of great relevance to the inference task. For example, social networks have access to individual attributes and variables as well as connective attributes. Still, prior to the work in our group, a systematic and comprehensive approach to community detection with side information was unavailable. We are dedicated to the development of the field of graph inference in the presence of non-graph data (side information), and to address the relevant challenges and explore the accompanying opportunities.
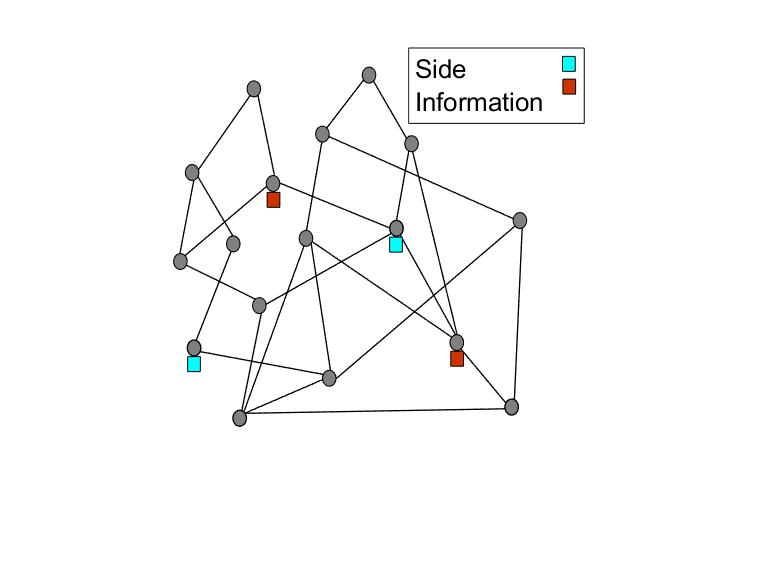
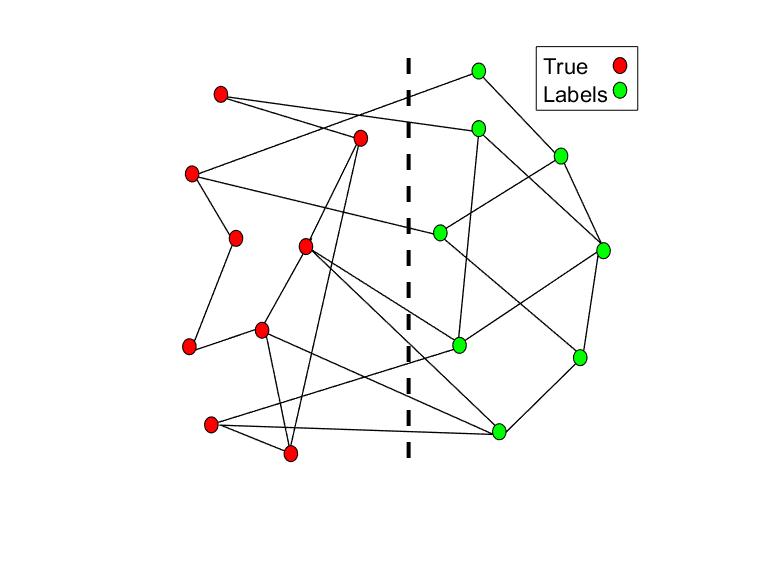
Our work investigates the impact of non-graph information on the exact recovery, weak recovery, and correlated recovery threshold. Among other things, we have been able to calculate the impact of side information variables with infinite cardinality, or even continuous valued side information. The effect on binary community detection and on detection of a hidden (single) community has been analyzed. Our newest work addresses the role of non-graph information in the exact recovery threshold of efficient algorithms such as semi-definite programming (SDP). For more, please see our publications.
Deep Learning
(1) Deep learning for graph inference
(2) Transfer learning, deep learning in the absence of large set of labeled data.