
Manipulation and Navigation
Robotic Grasping
Manipulation Trajectory Optimization
Topological Navigation
Neural Autonomous Navigation
Perception
Interactive Perception
Unseen Object Instance Segmentation
Few-Shot Object Recognition
Unseen Object Pose Estimation
Hand-Object Interaction
Transparent Object Recognition
6D Object Pose Estimation
Semantic Mapping
Multi-Object Tracking
Object Category Detection and Pose Estimation
Deep Metric Learning
Robotic Grasping

6D robotic grasping beyond top-down bin-picking scenarios is a challenging task. A robot needs to deal with various objects with different shapes and materials. In addition, robots may use different end-effectors such as grippers with different numbers of fingers. How to plan grasps and transfer grasps across different grippers is a challenging problem.
- MultiGripperGrasp : A Dataset for Robotic Grasping from Parallel Jaw Grippers to Dexterous Hands (IROS 2024)
- SceneReplica: Benchmarking Real-World Robot Manipulation by Creating Reproducible Scenes (ICRA 2024)
- NeuralGrasps: Learning Implicit Representations for Grasps of Multiple Robotic Hands (CoRL 2022)
- Hierarchical Policies for Cluttered-Scene Grasping with Latent Plans (RA-L 2022)
- Learning closed-loop control policies for 6D grasping (CoRL 2021)
Manipulation Trajectory Optimization

In robot manipulation, planning the motion of a robot manipulator to grasp an object is a fundamental problem. A manipulation planner needs to generate a trajectory of the manipulator to avoid obstacles in the environment and plan an end-effector pose for grasping. While trajectory planning and grasp planning are often tackled separately, how to efficiently integrate the two planning problems remains a challenge. We present novel methods for joint motion and grasp planning.
- Grasping trajectory optimization with point clouds (IROS 2024)
- The OMG-Planner integrates manipulation trajectory optimization with online grasp synthesis and selection (RSS 2020).
Topological Navigation
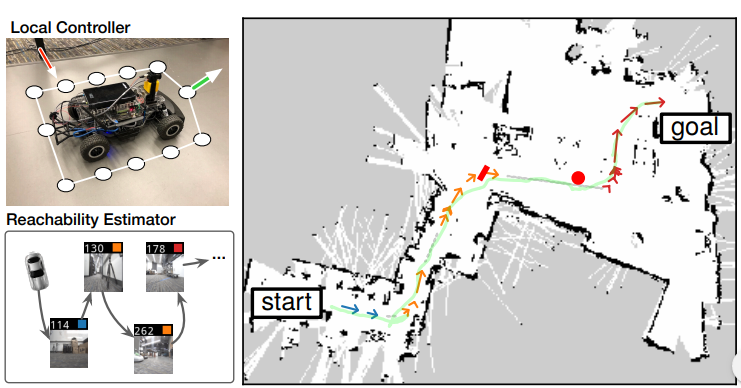
Compared to the traditional mapping, localization and planning approach (SLAM) that builds a metric map, visual topological navigation eliminates the need of meticulously reconstructing an environment which requires expensive or bulky hardware such as a laser scanner or a high-resolution camera. A robot needs to achieve spatial reasoning based on its experiences in the environments. We study how to build large-scale topological maps of real-world environments for efficient robot navigation (ICRA 2020, RA-L 2021).
Neural Autonomous Navigation
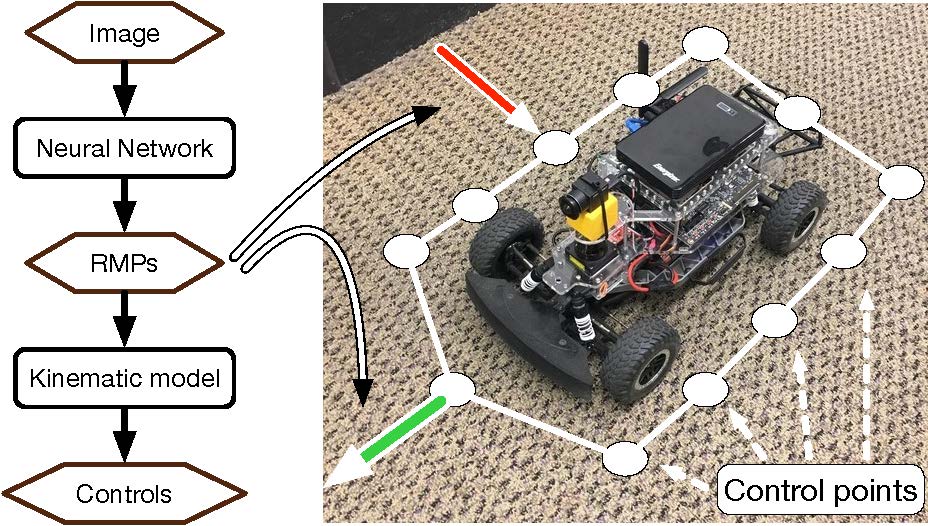
End-to-end learning for autonomous navigation has received substantial attention recently as a promising method for reducing modeling error. However, its data complexity, especially around generalization to unseen environments, is high. We introduce a novel image-based autonomous navigation technique that leverages in policy structure using the Riemannian Motion Policy (RMP) framework for deep learning of vehicular control. We design a deep neural network to predict control point RMPs of the vehicle from visual images, from which the optimal control commands can be computed analytically (ICRA 2019).
Interactive Perception
Robots can interact with objects and environments in order to learn from the interactions. Compared to learning from a static dataset, interactive perception enables robots to acquire data actively to improve their perception skills.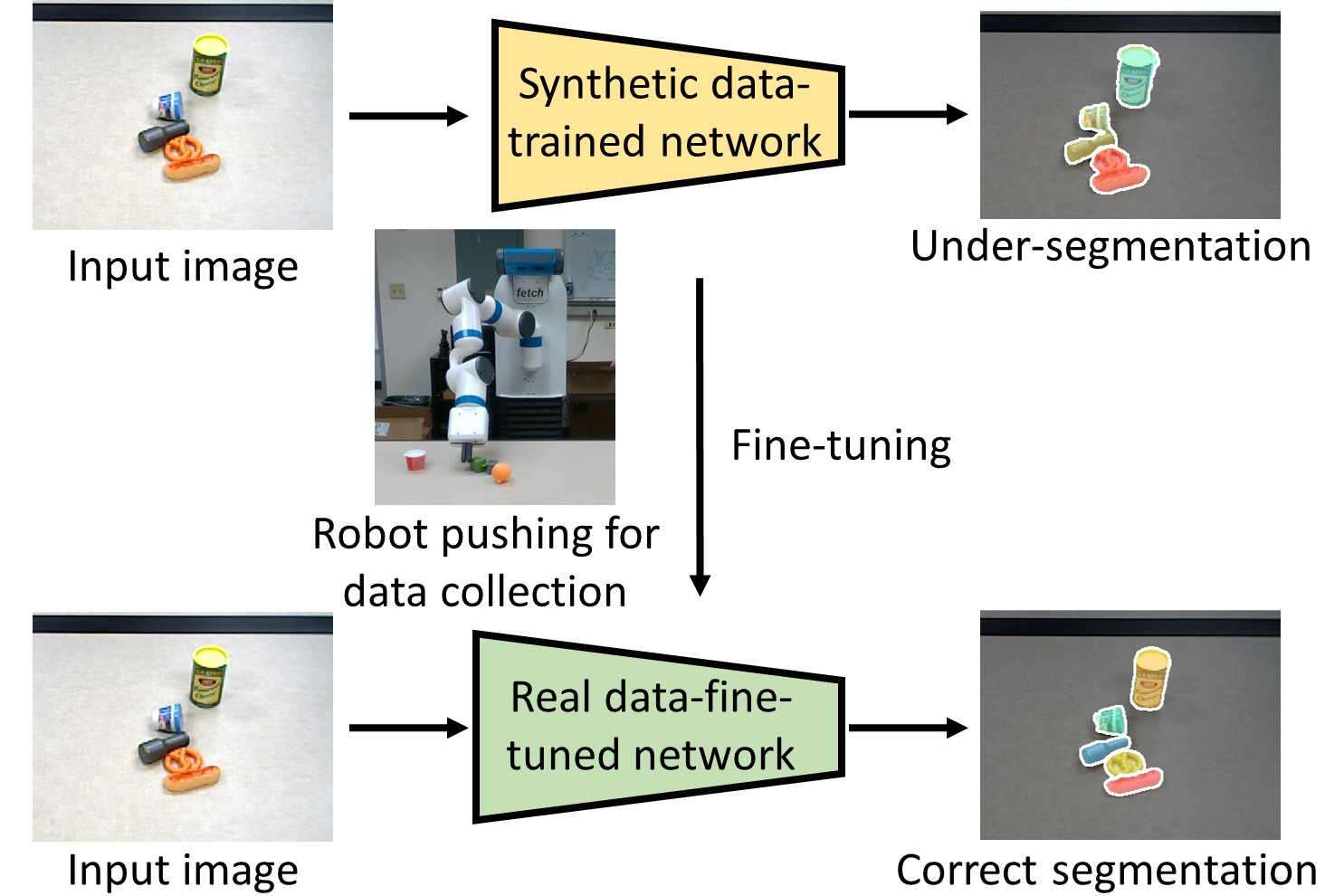
- Body frame-invariant features for interactive object segmentation (ICRA 2024)
- Long-term robot interaction to improve object segmentation (RSS 2023)
Unseen Object Instance Segmentation
Segmenting unseen objects in cluttered scenes is an important skill that robots need to acquire in order to perform tasks in new environments. We have studied different ways to segment unseen objects by exploring different cues from images or videos.
- Mean Shift Mask Transformer for unseen object instance segmentation (ICRA 2024)
- Segmentation refinement with graph neural networks (CoRL 2021)
- Segmenting unseen objects by learning RGB-D feature embeddings (CoRL 2020)
- Segmenting unseen objects by leveraging depth and RGB separately (CoRL 2019, T-RO 2021)
- Segmenting moving objects from videos based on motion (CVPR 2019)
Few-Shot Object Recognition

Few-shot learning emphasizes learning from a few examples per object. if robots can recognize objects from a few exemplar images, it is possible to scale up the number of objects a robot can recognize since collecting a few images per object is a much easier process compared to building a 3D model of an object.
- The Proto-CLIP model, a vision-language prototypical network for few-shot learning (IROS 2024)
- The FewSOL dataset of few-shot object recognition (ICRA 2023)
Unseen Object Pose Estimation
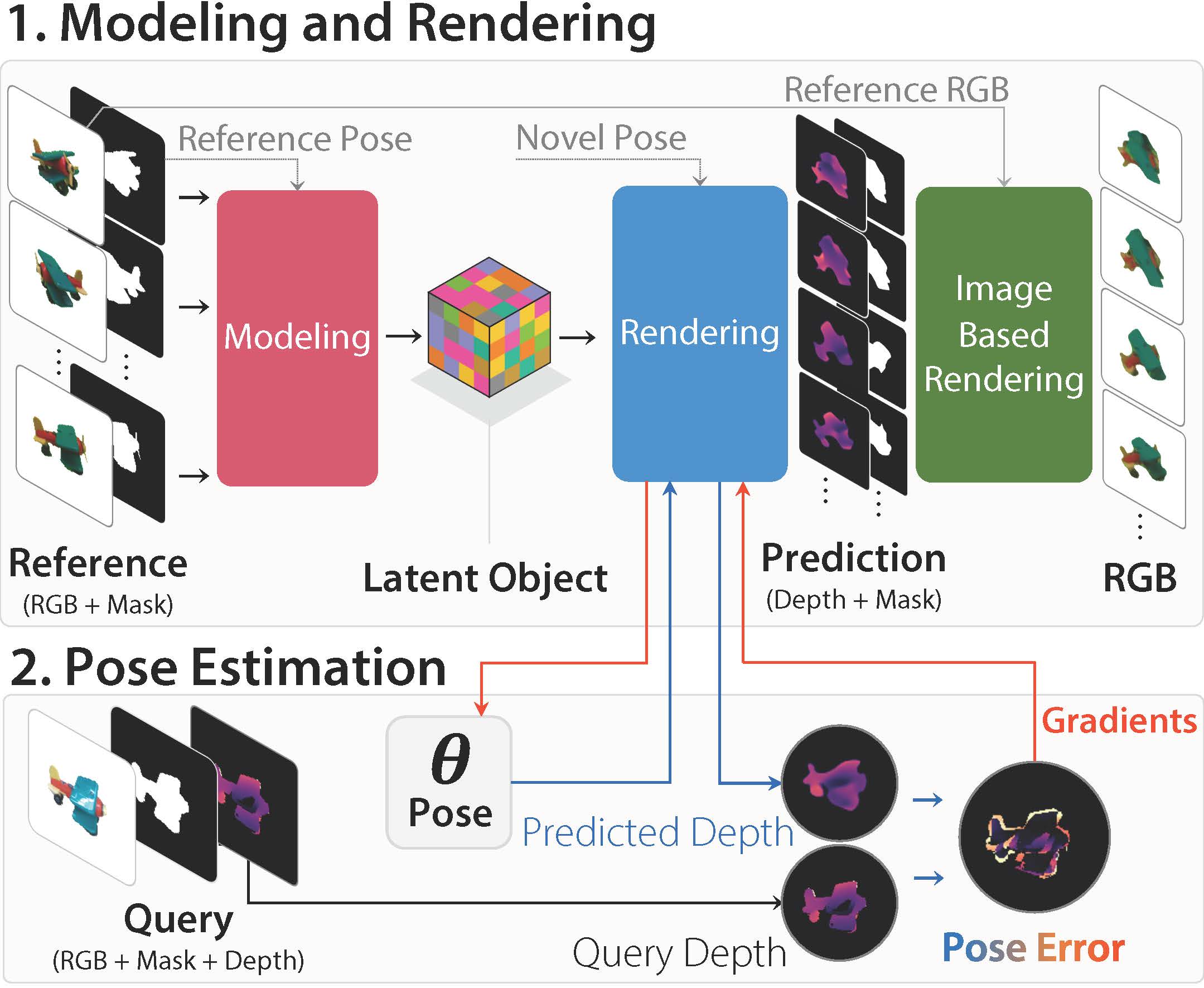
We introduce LatentFusion, a novel framework for 6D pose estimation of unseen objects. We present a network that reconstructs a latent 3D representation of an object using a small number of reference views at inference time. Our network is able to render the latent 3D representation from arbitrary views. Using this neural renderer, we directly optimize for pose given an input image (CVPR 2020).
Hand-Object Interaction


We introduce a new dataset for hand-object interaction named DexYCB. We set up a multi-camera motion capture system to collect videos of humans grasping and handling objects. Then we can register 3D models of hands and objects to the collected RGB-D videos. Our dataset can be useful to study and benchmark hand-object interaction (CVPR 2021).
Transparent Object Recognition
![]()
Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this work, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed (CVPR 2021).
6D Object Pose Estimation
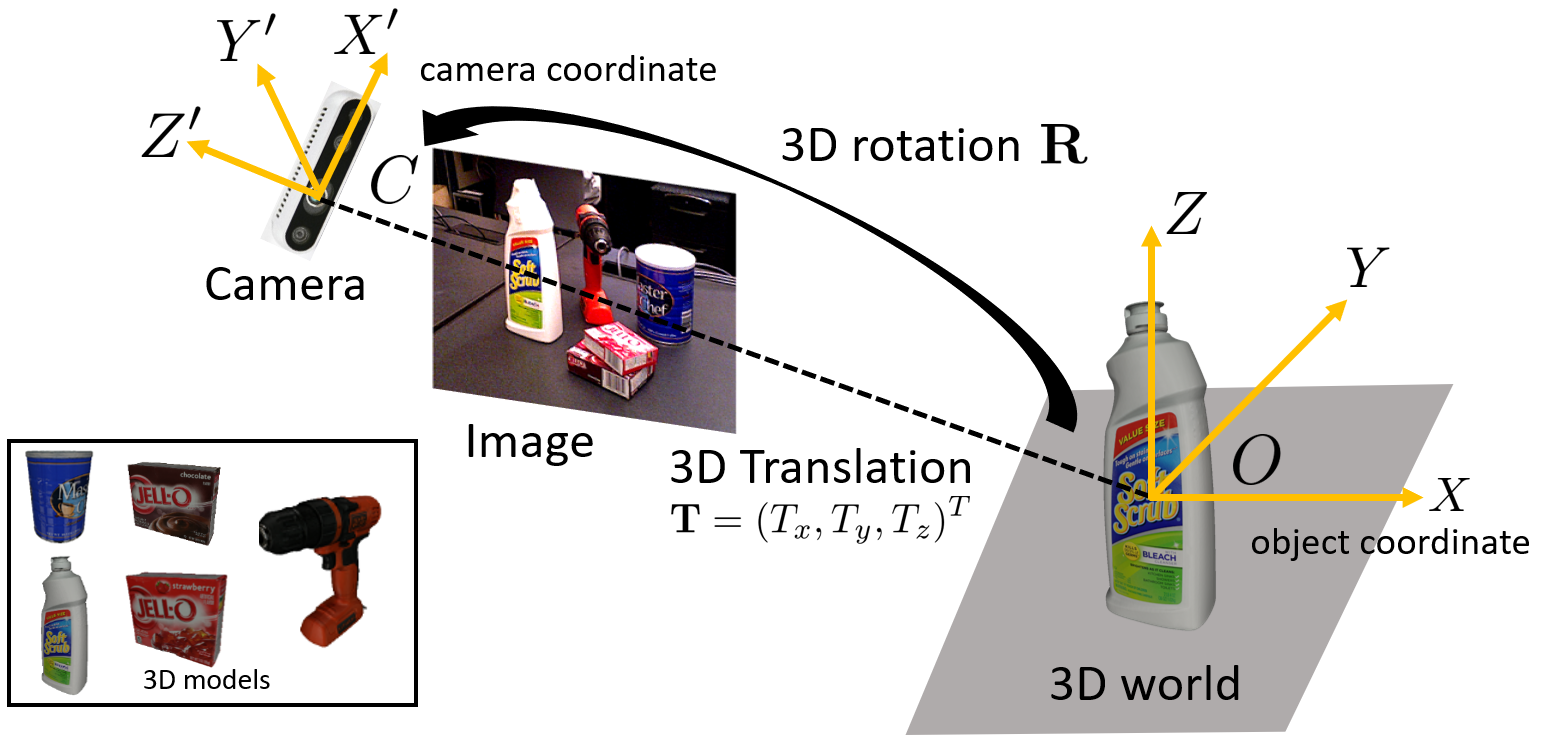
Estimating the 6D pose of known objects is important for robots to interact and manipulate objects. The problem is challenging due to the variety of objects as well as the complexity of a scene caused by clutter and occlusions between objects. We have studied different mechanisms for 6D object pose estimation combining deep neural networks with geometric reasoning.
- PoseRBPF: A Rao-Blackwellized Particle Filter for 6D Object Pose Tracking (RSS 2019, T-RO 2021)
- Self-supervised 6D Object Pose Estimation (ICRA 2020)
- DOPE: Deep Object Pose Estimation (CoRL 2018)
- DeepIM: Deep Iterative Matching for 6D Pose Estimation (ECCV 2018, IJCV 2020)
- PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation (RSS 2018)
Semantic Mapping
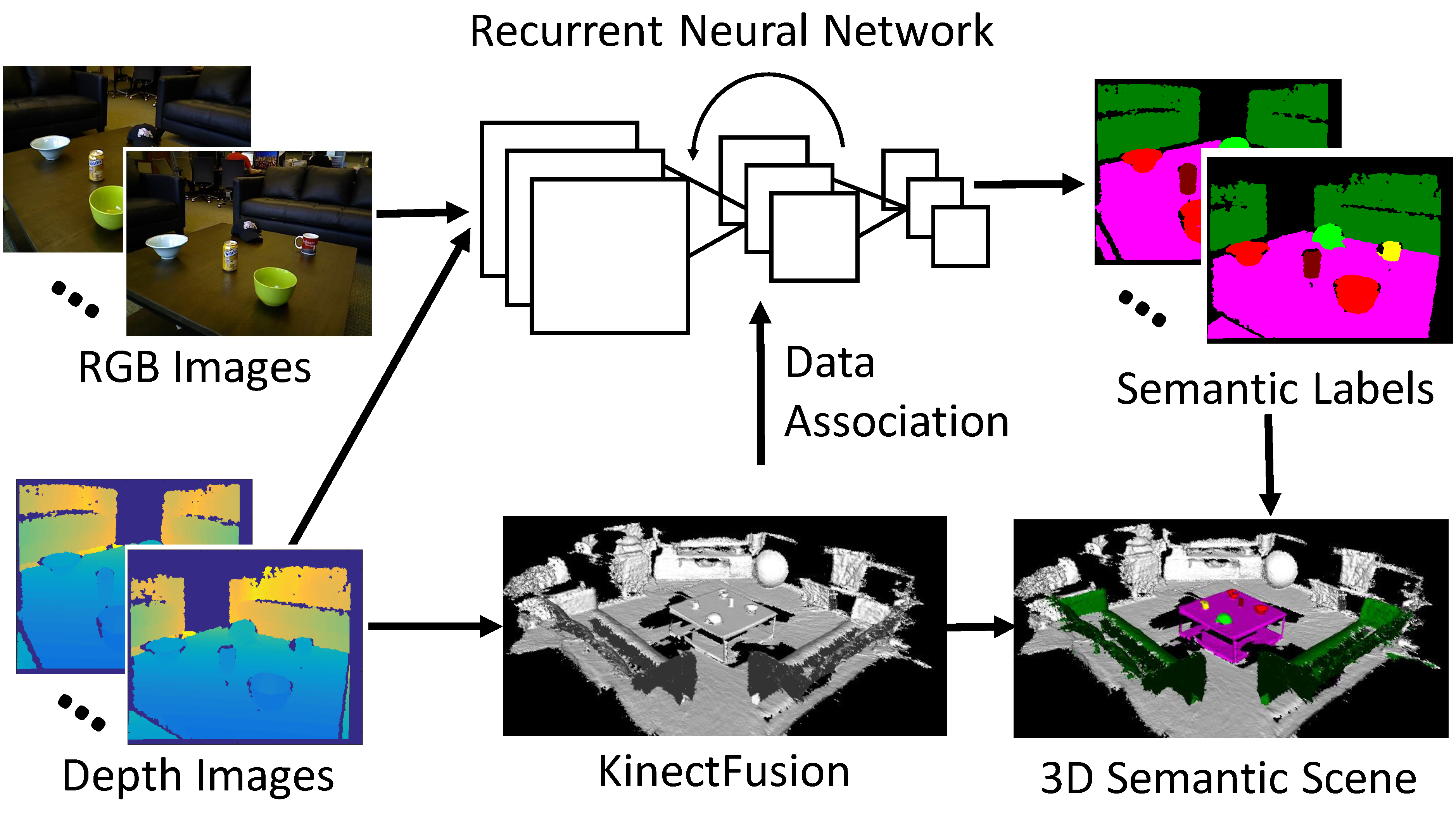
3D scene understanding is important for robots to interact with the 3D world in a meaningful way. Most previous works on 3D scene understanding focus on recognizing geometrical or semantic properties of a scene independently. In this work, we introduce Data Associated Recurrent Neural Networks
(DA-RNNs), a novel framework for joint 3D scene mapping and semantic labeling (RSS 2017).
Multi-Object Tracking

Multi-Object Tracking (MOT) has wide applications in time-critical video analysis scenarios, such as robot navigation and autonomous driving. In tracking by-detection, a major challenge of online MOT is how to robustly associate noisy object detections on a new video frame with previously tracked objects. We have studied using Markov Decision Processes and Recurrent Autoregressive Networks to improve online MOT.
- Recurrent Autoregressive Networks for online MOT (WACV 2018)
- Markov Decision Processes for online MOT (ICCV 2017)
Object Category Detection and Pose Estimation
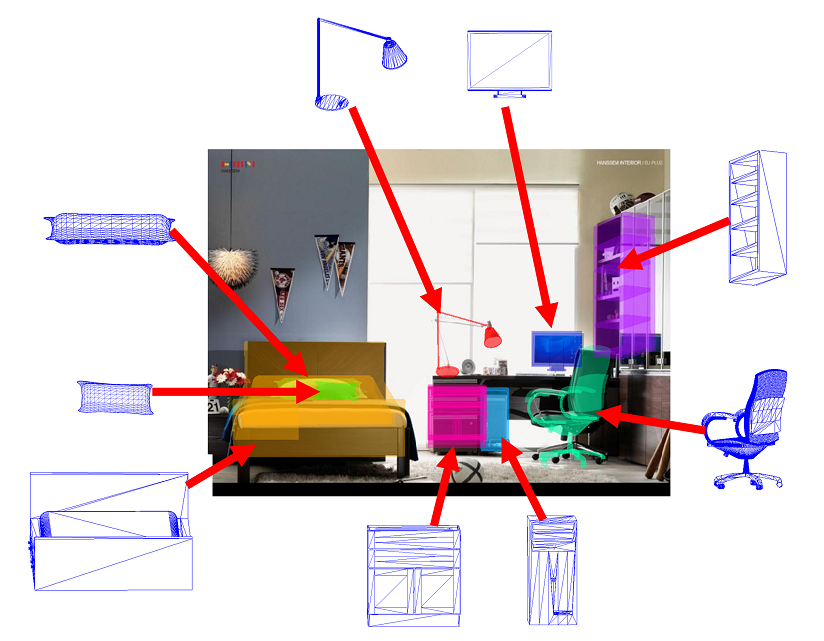
We study how to detect objects among specific categories and estimate the 3D poses of the detected objects from 2D images. We utilize 3D models of objects to learn useful category-level 3D object representations for recognition. We also contributed two useful datasets for 3D object detection and pose estimation.
- ObjectNet3D: A Large Scale Database for 3D Object Recognition (ECCV 2016)
- PASCAL3D+: A Benchmark for 3D Object Detection in the Wild (WACV 2014)
- 3D Voxel Patterns for Object Category Recognition (CVPR 2015, WACV 2017)
- Aspect Layout Models for 3D object Recognition (CVPR 2012, ECCV 2012, 3dRR 2013, ECCV 2014)
Deep Metric Learning
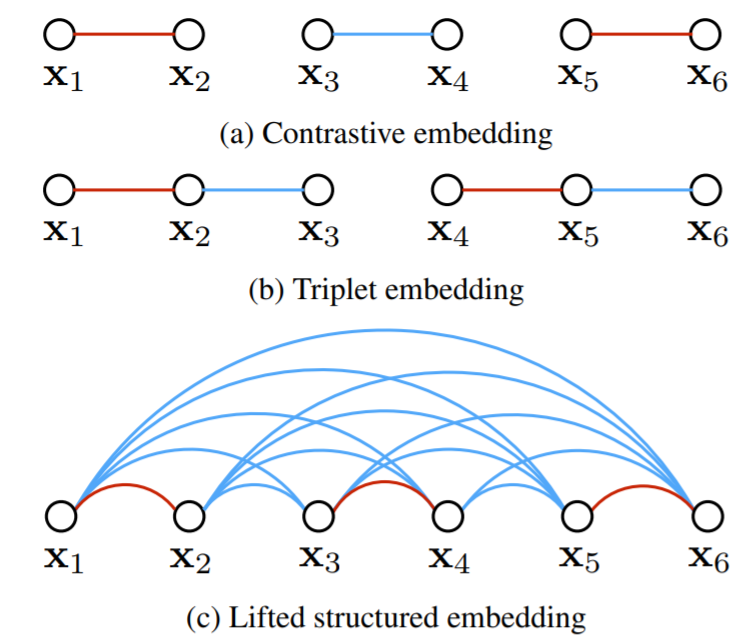
Learning the distance metric between pairs of examples is of great importance for learning and visual recognition. In this work, we describe an algorithm for taking full advantage of the training batches in the neural network training by lifting the vector of pairwise distances within the batch to the matrix of pairwise distances. This step enables the algorithm to learn the state of the art feature embedding by optimizing a novel structured prediction objective on the lifted problem (CVPR 2016).